
PICU患者死亡率预测:多模型机器学习全流程实现
Published:
项目背景
儿科重症监护室(PICU)患者的住院死亡率预测是临床风险评估中的重要问题。由于PICU患者病情复杂、死亡率相对较低,传统统计方法在非线性建模与风险分层方面存在一定局限。
本项目基于PICU真实临床表格数据,构建了一个端到端的机器学习预测流程,系统比较了 Logistic 回归、随机森林(Random Forest)与支持向量机(SVM)三类模型,并通过多维度评估与特征贡献分析,探索关键临床变量对死亡风险的影响。
数据概览与结局分布
数据集包含约 8,952 条 PICU 住院记录,结局变量为院内死亡(HOSPITAL_EXPIRE_FLAG)。死亡率约为 7.5%,呈现出明显的类别不平衡特征,这对模型训练与评估提出了更高要求。
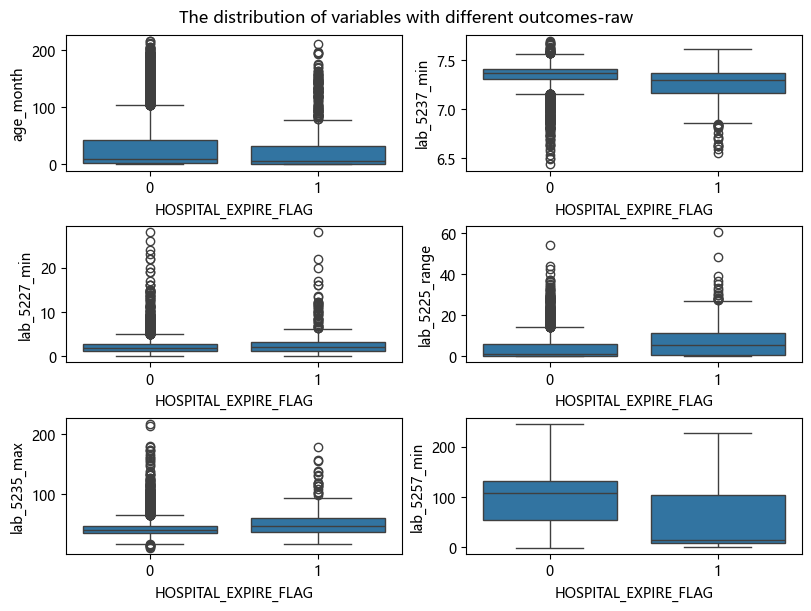
数据缺失情况分析
在建模前,对各变量的缺失情况进行了系统分析。部分连续临床变量(如化验指标)存在不同程度的缺失,但未发现全缺失或完全无信息的变量。
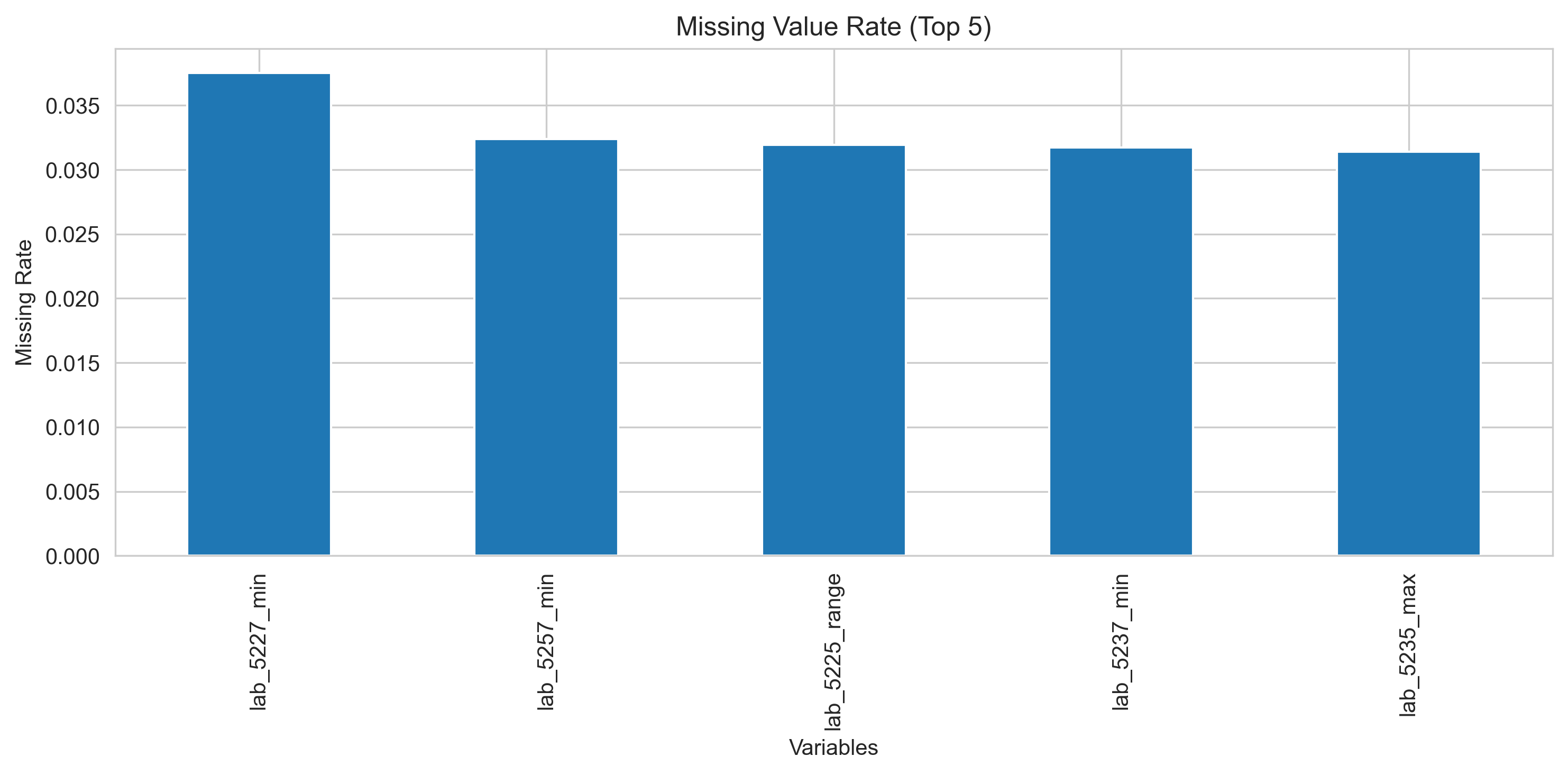
数据清理与预处理策略
缺失值处理
- 连续变量:中位数填补(Median Imputation)
- 优点:对偏态分布与极端值更稳健
- 所有填补参数仅在训练集上拟合,避免信息泄漏
异常值处理
- 采用 Winsorization(1%–99% 分位截断)
- 目的:降低极端异常值对模型训练的影响,而不直接删除样本
特征标准化
- 对连续变量进行 Z-score 标准化
- 提升 Logistic 回归与 SVM 的数值稳定性
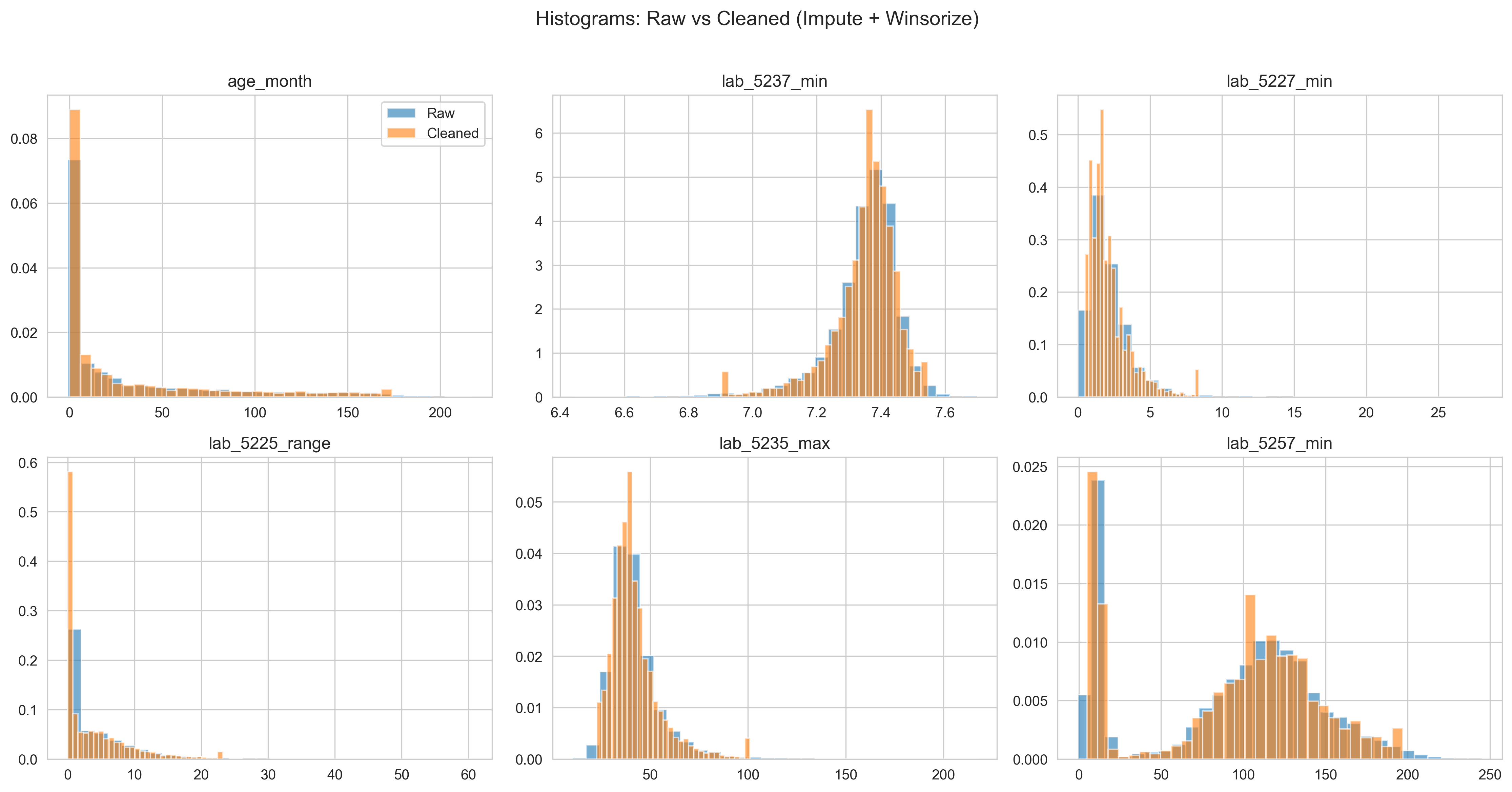
数据清理前后分布对比(可视化证据)
为了直观展示数据清理的效果,对核心连续变量绘制了 清理前(Raw)与清理后(Cleaned) 的分布对比。
直方图对比(Raw vs Cleaned)
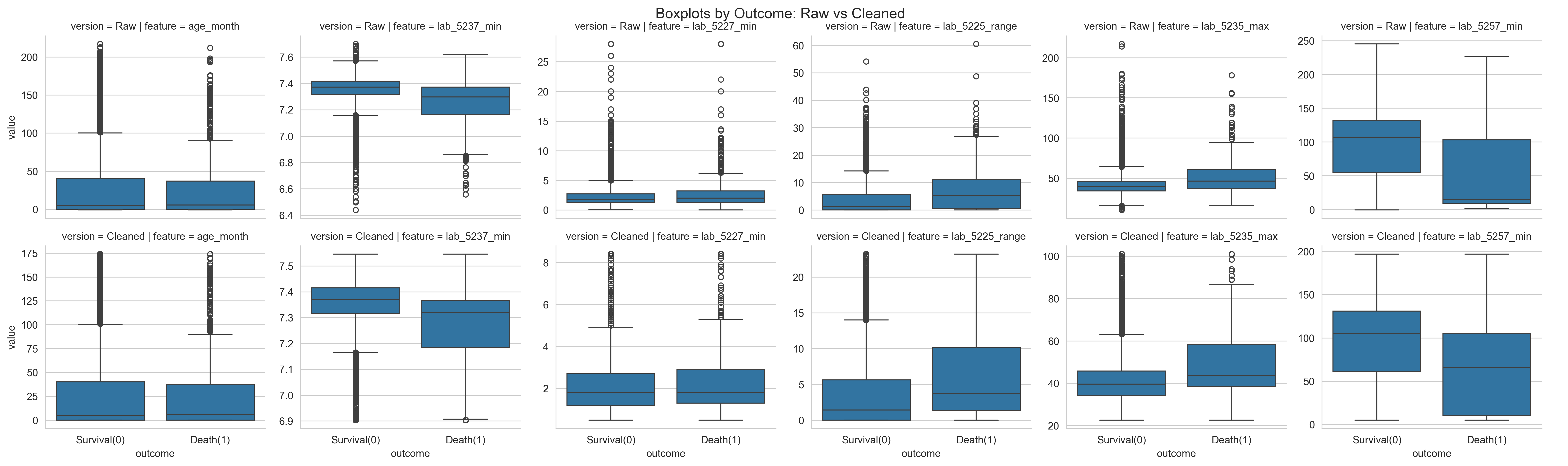
按结局分组的箱线图对比
模型训练与调参策略
本项目对比了三类常见但互补的机器学习模型:
- Logistic Regression(L2 正则)
- 可解释性强,作为 baseline 模型
- Random Forest
- 捕捉非线性关系与特征交互
- 对异常值与尺度不敏感
- SVM(RBF Kernel)
- 具备灵活的非线性判别能力
训练策略
- 数据划分:70% 训练集 / 30% 测试集(分层抽样)
- 超参数调优:5 折分层交叉验证 + GridSearch
- 主要优化指标:ROC-AUC
- 类不平衡处理:
class_weight="balanced"或balanced_subsample
模型评估结果
判别能力(ROC & PR)
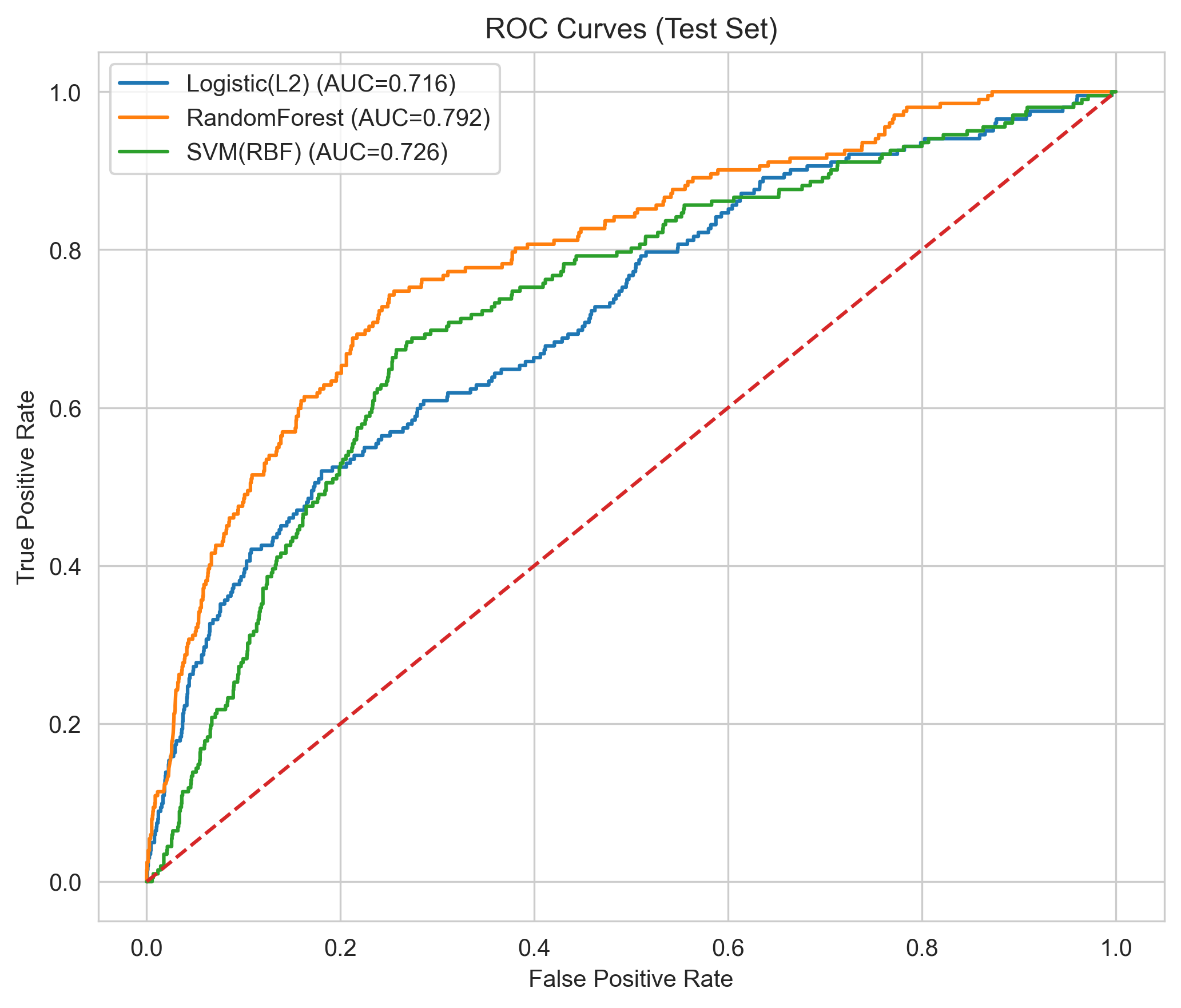
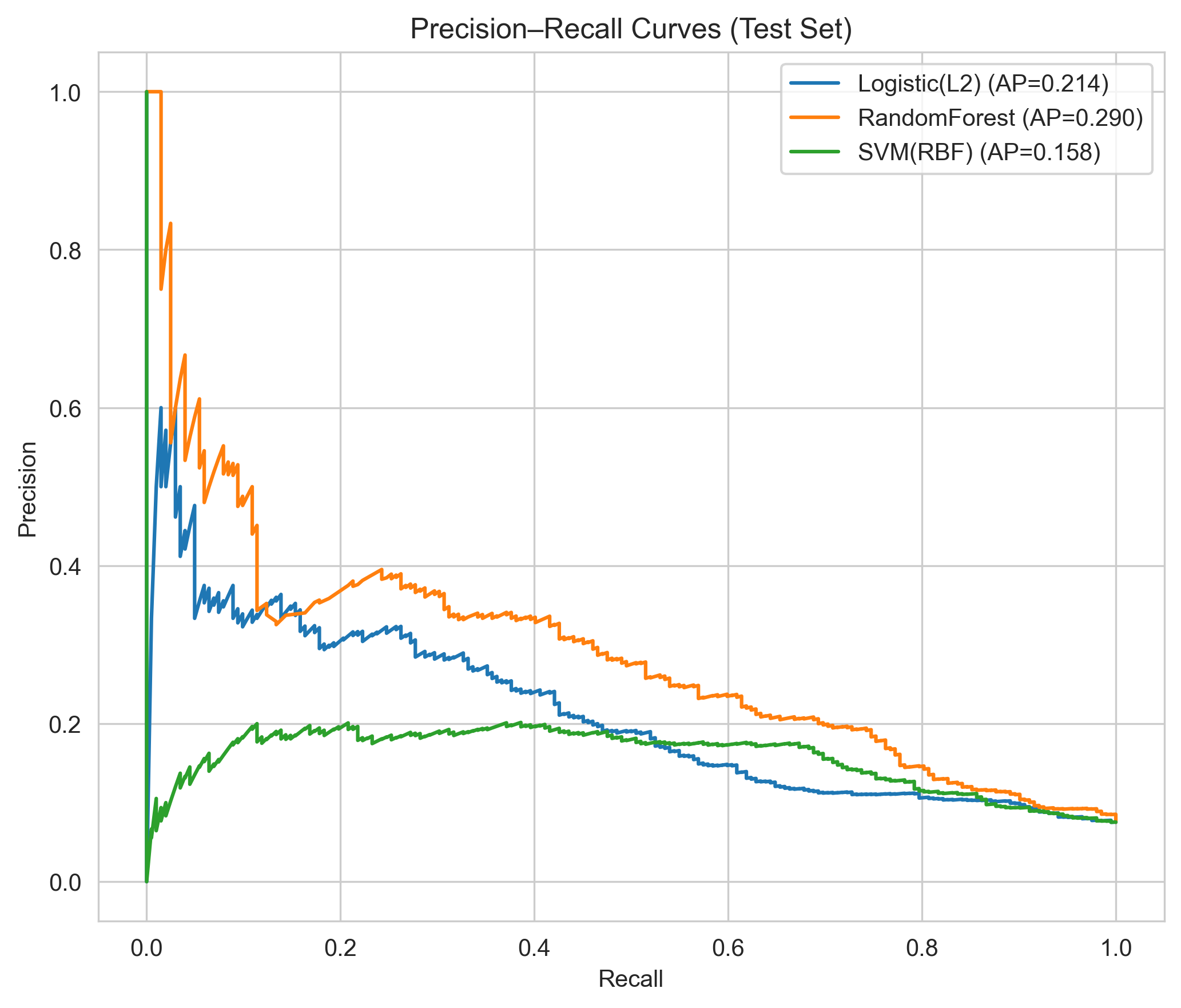
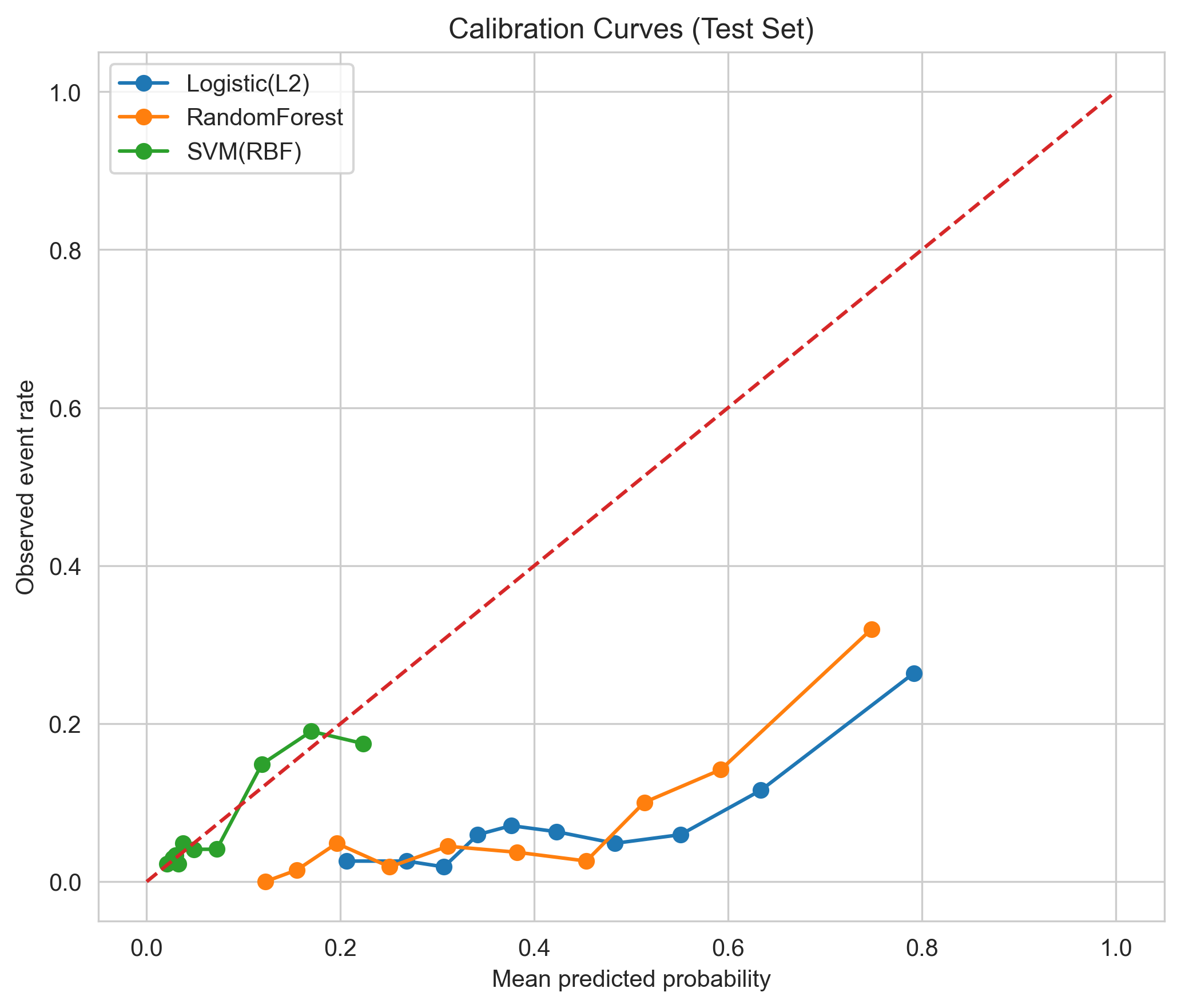
校准性能(Calibration)
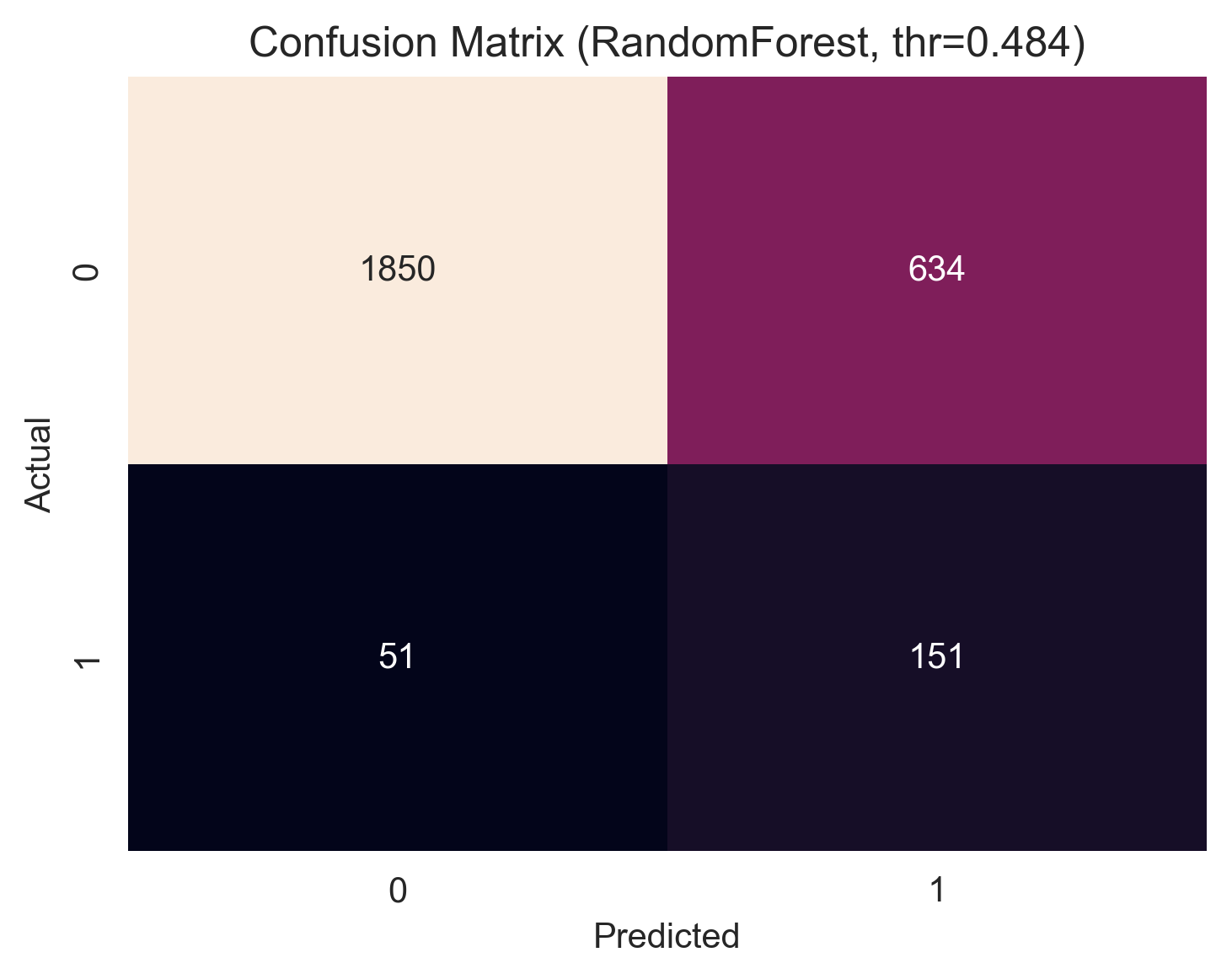
阈值决策与混淆矩阵
采用 Youden Index 在测试集上选择最优阈值,得到一个兼顾敏感性与特异性的工作点。
特征贡献与模型可解释性
为避免“黑箱模型”,本项目从两个角度分析特征贡献:
Random Forest 内置重要性(Gini Importance)
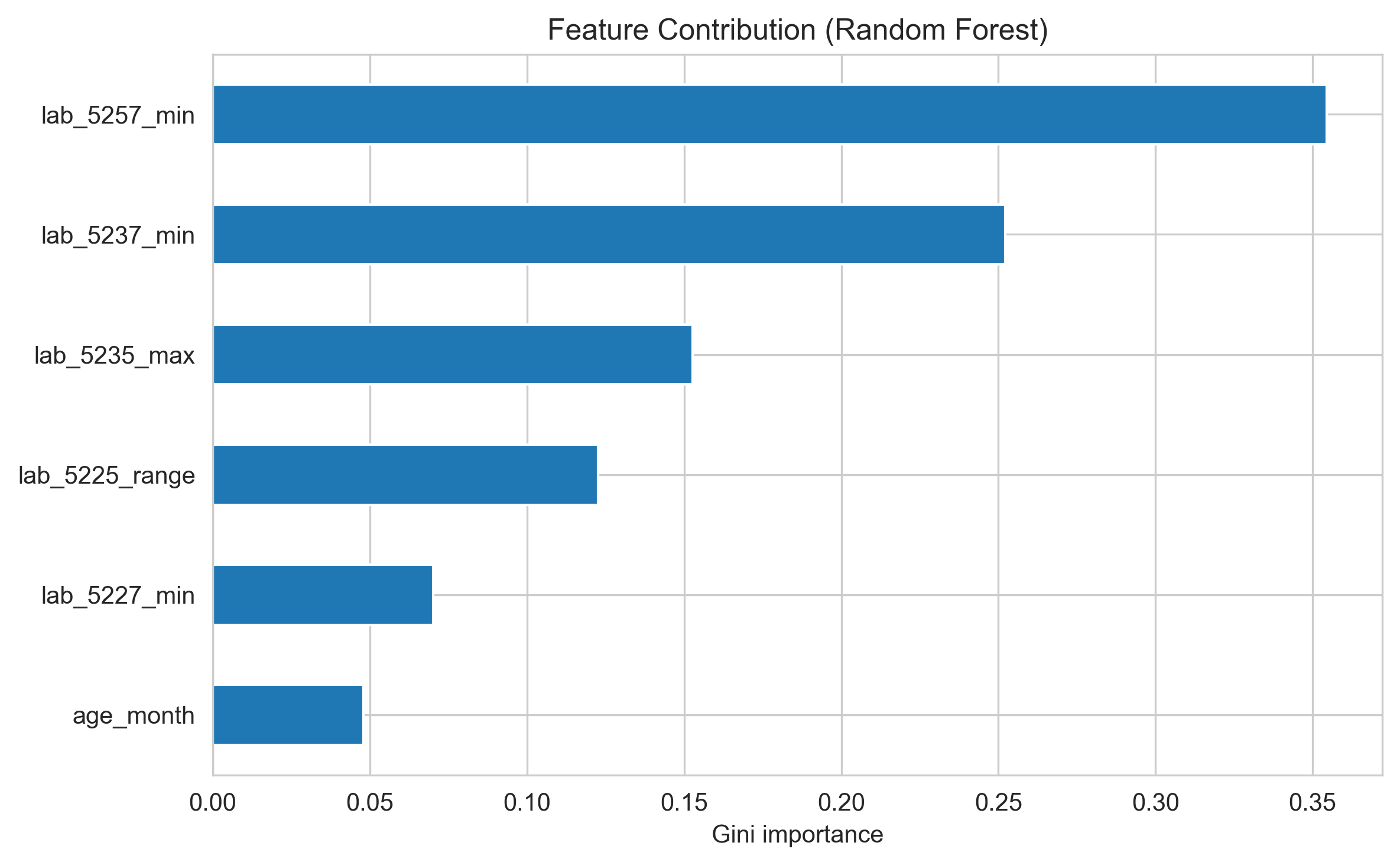
Permutation Importance(测试集)
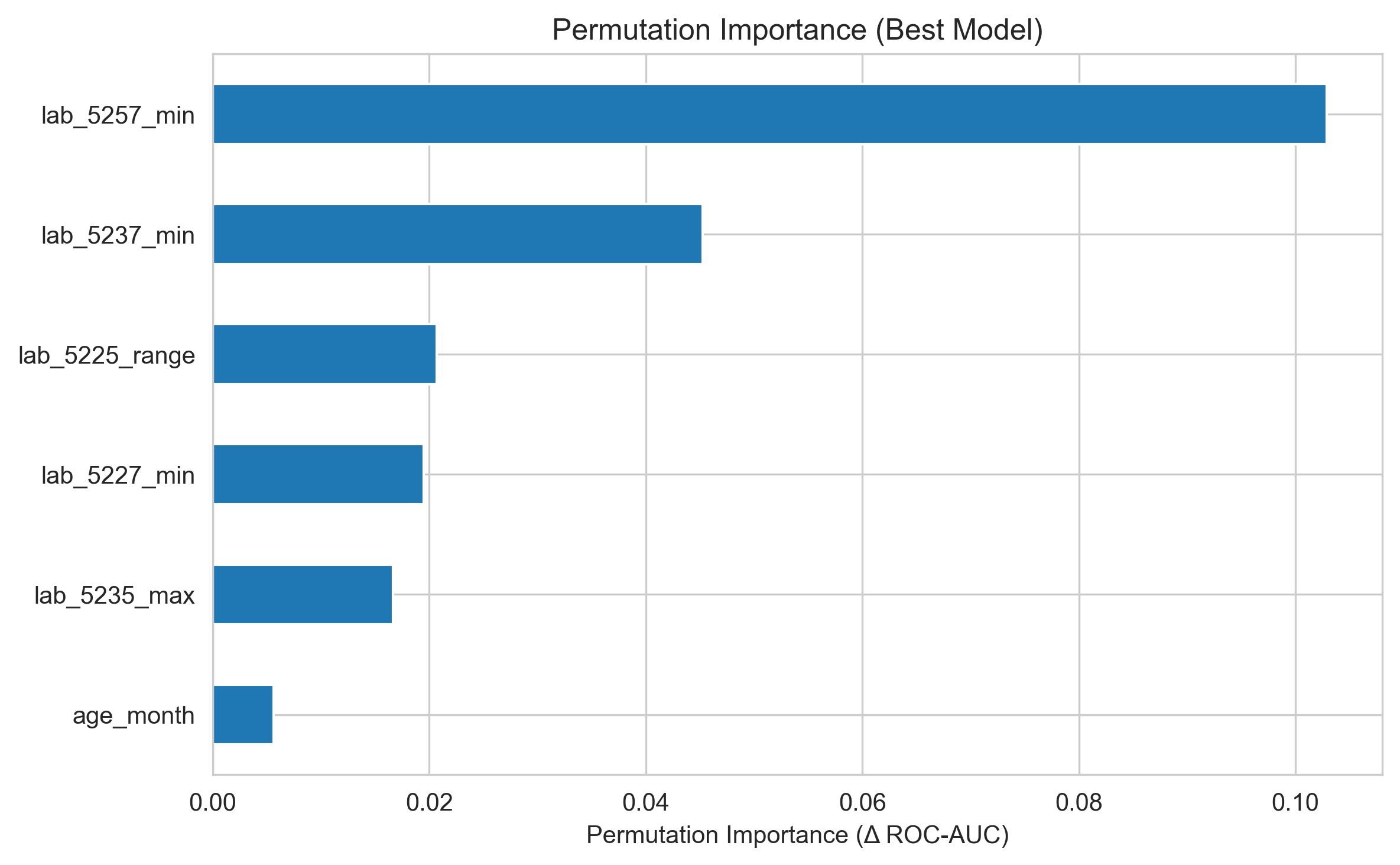
结论与下一步工作
主要结论:
- Random Forest 在该 PICU 数据集上取得最佳整体表现(AUC≈0.79,AP≈0.29)
- 数据清理(中位数填补 + Winsorization)显著提升模型稳定性
- 特征贡献分析能够稳定识别与死亡风险相关的关键临床变量
下一步方向:
- 引入更多时间序列特征(生命体征动态变化)
- 尝试 Gradient Boosting(XGBoost / LightGBM)
- 构建简单 Web 界面,实现临床风险在线评估
- 外部数据集验证模型泛化能力